Extracting PBMCs For Downstream RNA sequencing

I'm about 28 months out from my primary Covid19 infection that caused my hospitalization, and eventually gave me the joy of long covid. While everyone has their own unique presentation, my day to day usually involves frequent periods where I feel ill and exhausted. I like to walk, and often when I'm feeling good I can do a lap or two around the block. But more often than not, especially lately, I can go from feeling about 80% to feeling about 20% in the space of about 100m or so. When a crash happens, it sort of feels like every cell in my body just suddenly runs out of energy - my heart, my brain, my muscles. Brain fog usually intensifies, my autonomic system feels unstable, and I feel like I have low blood sugar (even though I don't). It's a horrible feeling that if it happened to someone who wasn't used to it, might prompt a visit to the ER or at least their family doctor as it's not subtle at all.
As such, I've become mostly singularly-focused on trying to figure out how to improve. I'm able to still work a day job, at least part time, and have enough engineering projects to keep my brain happy. But what time I don't spend on those things I've been using to slowly unravel my own situation using whatever technology I can.
I originally did RNA sequencing via the Amatica project, which was informative and useful as a long covid baseline. Since then I've done several other RNA sequencing rounds at various providers in Europe, slowly adding to my personal collection of data. I built a RNA pipeline called Chimera by cobbling together a lot of open source pieces, so I'm able to analyze them all on my own. Thanks to the existence of many public datasets that include FASTQ files, I've been able to come up with several useful control datasets for ribo-depleted, poly-a, and even PBMC datasets. Because they weren't run on the same machines and in the same labs, I've had to come up with a few normalization methods that rely on a curated list of house keeping genes. That seems to bring most datasets into rough alignment. It probably makes the genes that are minimally expressed less certain, but I'm pretty confident that if something has a z-score of +5 when compared to 40 roughly age-matched controls, that it's likely a high enough signal that I can put some weight on.
Recently I stumbled upon a company called Plasmidsaurus that offers RNA seq with the added benefit of being able to produce results in 48 hours. That's pretty incredible considering most of my other RNA seq has taken between 6 weeks and several months to come back. The problem with that time lag is I can't use it to determine whether or not any treatments I'm trialing are having any impact, since by the time the data comes back my experiment is often over. It's still useful as data that I can look back on, but less useful for understanding what's happening in pseudo real time. Plasmidsaurus I thought might be useful as an adjunct to my other sequencing - the one catch though is they don't support whole blood, and only can handle cells suspended in Zymo's RNA/DNA shield product.
So, in order to take advantage of their service, I had to figure out how to extract my own PBMC cells at home using what I have in terms of equipment, and augmenting that with a few deliberate purchases.
Density Gradient Tubes
PBMCs are Peripheral Blood Mononuclear Cells - they are the cells in the blood with a round nucleus, namely lymphocytes and monocytes. They are arguably the best cells to work with when trying to understand immune disorders as they aren't polluted with neutrophils or globin which can make interpreting whole blood RNA sequencing a bit trickier.
There a few different methods around for extracting them from whole blood, but I opted to use a special tube called a density gradient tube (DGT) to extract mine. In my case I chose Plurimate II tubes, which one of my suppliers offered.
These tubes have a barrier at the bottom, a fine mesh I imagine. You basically put 4.5ml of a special liquid in the tube that has a known density, and spin it in the centrifuge to set it below the barrier. Then, you slowly trickle whole blood on top, and run the entire tube in a centrifuge. As the tube spins, the neutrophils and red blood cells are forced below the fine mesh, causing the liquid medium to be pushed upward. Because of its carefully chosen density, the PBMCs are pushed upwards along with it, leaving the red blood cells etc trapped below the mesh.
Here is a photo of 9ml of my blood next to a 15ml DGT with 4.5ml of density medium in it.
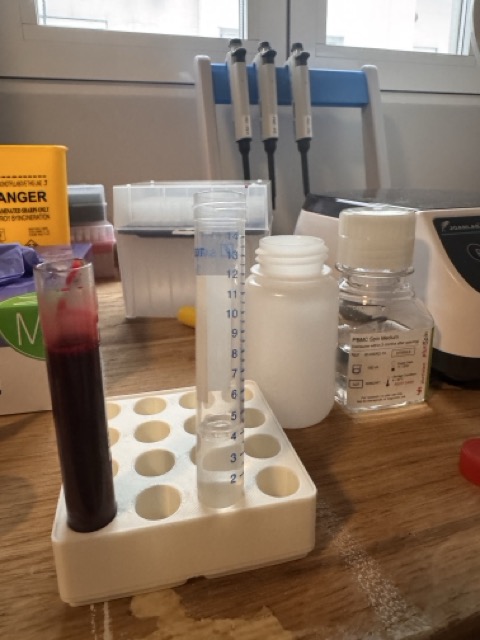
After moving the 9ml of blood into the DGT, it basically looks like this and is ready for centrifuging.
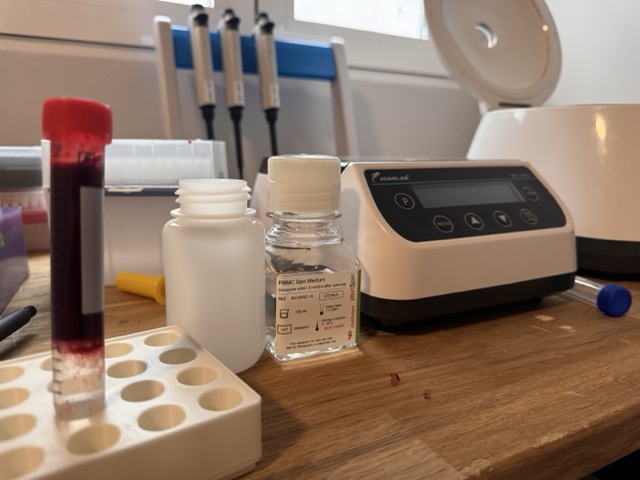
Next step is to centrifuge the entire tube at 800g for about 15 minutes, which causes the actual separation to occur. I think technically it's best to use something called a swinging rotor centrifuge, which results in a nice clear horizontal transition. I don't have one of those, and so far it doesn't seem to have impacted me.
When you remove the tube from the centrifuge, you can see the clear separation of layers. The red blood cells have migrated below the barrier, the PBMC liquid has risen above that (the transparent liquid above the blood cells), and there now exists a layer of plasma on top. The transition layer between the serum and the density medium, which is sort of cloudy, is called the buffy coat, and it contains the PBMC cells.

Separating the PBMC Cells
The plasma actually can be saved, which I've been doing since it just adds to my longitudinal n=1 data set I have in my own personal Brundle Museum of Natural history in my freezer. I'm not sure if I'll ever use it, but might as well save it just in case (my frozen serum already came in handy back-filling some antibody tests after the fact). I put these in 1.8ml cryovials along with a label + QR code so I can remember what each sample was and when it was taken.
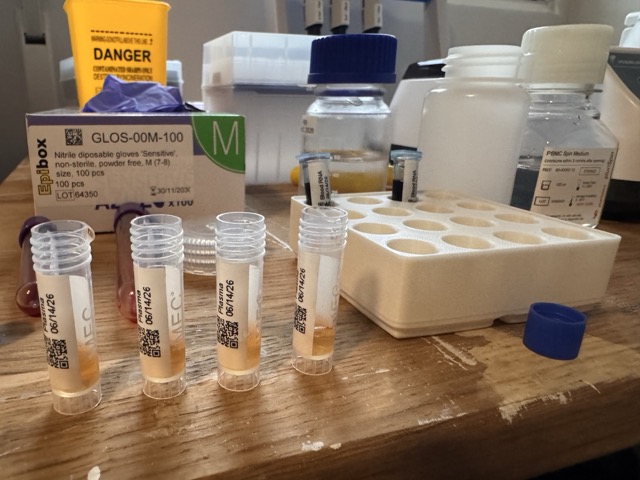
Washing The PBMCs
Once the serum has been carefully removed (I only remove everything up until about 1ml above the buffy coat so I don't accidentally disturb it), I transfer all the liquid into a new 15ml centrifuge tube. Due to the DGT barrier, you can mostly just pour it in, being careful not to allow any red blood cells to trickle in.
Right now you have a mixture of PBMCs, serum, and density gradient material, which isn't what you want to end up with. So the next step is called washing the PBMCs, and it involves adding phosphate-buffered saline (PBS) to the mixture, centrifuging it, then removing the liquid that's left. This washes away, via dilution basically, all the liquid you don't want, leaving the PBMCs nice and clean.
After adding my PBS to the 15ml tube, it looks like this, ready for centrifuging.

Concentrating The PBMC Layer
Next, the 15ml tube is centrifuged at 400g for about 15 minutes. This causes all the PBMC cells to concentrate on the bottom of the tube, while the wash solution consolidates above. This small little solid mass of PBMCs is known as a 'pellet', and it's quite small. The actual amount of PBMC cells in whole blood is just a small percentage, so often in real studies they will take 30-40ml of whole blood I believe to have enough. I don't need a ton of RNA for what I'm doing, so 9ml's worth is enough for that. But as you can see based on the pellet size, you don't really get a ton of material, and a simple mistake can eliminate a lot of what you're after.
Here is a view of the pellet after coming out of the centrifuge.

Preparing For Submission To Plasmidsaurus
The next step is the one I'm still refining, as I don't quite feel I've gotten it right yet. After washing it, I need to get it down to a reasonable volume such that I can add Zymo DNA/RNA shield and submit 75ul of material to Plasmidsaurus. My current approach, after trial and error, is to transfer the pellet to a smaller 1.5ml micro-centrifuge tube, add more PBS to wash it again, and then re-pellet. My rationale for this is it's much easier to then add 200ul of DNA/RNA shield to a smaller tube than the larger 15ml tube. But this is still something I'm iterating on it. Every time you transfer the material I'm sure you lose some, so that's the trade off.
Here's a view of the final pellet after centrifuging the mini-centrifuge tube.
At this point, you're supposed to count how many cells you collected and then submit a certain amount of cells suspended in at least 50ul of DNA/RNA shield and submit to Plasmidsaurus. Unfortunately for me I don't have a cell counter, so I had to estimate it using general knowledge about how many PBMCs were in 1ml of whole blood, etc. I figured they would tell me if I was low or high, and I could use that to close the loop and improve each time. Here was the result of the first submission, with the result on Plasmidsaurus' side for how much RNA they detected. For reference, they want at least 10ng/ul, so I was short.
| Blood (ul) | Amount of Liquid (ul) | Measured RNA (ng/ul) | Amount |
|---|---|---|---|
| 8000 | 800 | 2.2 | Low |
To help figure out what I could do to improve it, I got AI to help me build a series of tools, one of which is a PBMC yield estimator. Using public information about PBMC cells / ml of blood, how much RNA is in each cell etc, I came up with this quick tool where I can estimate the results.
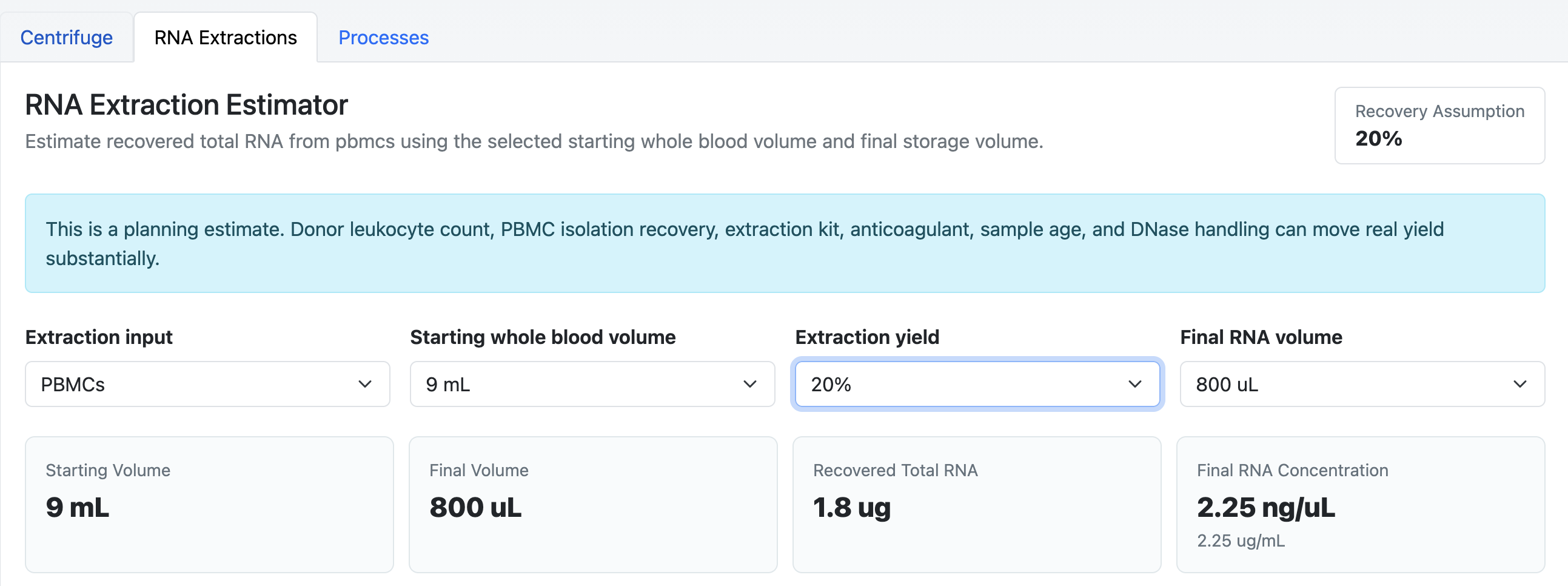
Using this tool I used the Plasmidsaurus data to backfill my process and estimated that my yield on extraction was about 20%, which makes sense because I think I butchered the buffy coat the first time I did it, and mostly grabbed the wrong layer (the density medium).
I figured on the next run I would get closer to 50%, so I dialled that in and changed how much DNA/RNA shield I used. I've now submitted three samples now, all of which were returned without 48 hours, and I have enough data to quantify my workflow now.
| # | Blood (ul) | Amount of Liquid (ul) | Measured RNA (ng/ul) | Est. Yield | Amount |
|---|---|---|---|---|---|
| 1 | 8000 | 800 | 2.2 | 22% | Low |
| 2 | 8000 | 200 | 21.1 | 55% | High |
| 3 | 10000 | 240 | 21.9 | 57% | High |
So I'm getting close to 60% extraction yield on my process, which is fine, as long as I know I'm in the ballpark for what they require, which is anywhere between 10ng/ul and 50ng/ul - my goal is to be smack in the middle, which I mostly am now.
It takes me about an hour to do an extraction, but there is probably only 10 - 15 minutes of hands-on work. Since I need blood anyways, I usually also take a EDTA tube of whole blood and save a few 400ul blood samples at the same time which I plan to do qPCR on in the near future.
I'll do a post soon on my actual Plasmidsaurus results, and share some FASTQ files and differential expression tables for the keeners in the crowd who want to play with some of that stuff on their own.
When I first sat down to do this process, it seemed pretty daunting. But having done it a few times, it seems pretty simple in theory. I hope that's the same with the RNA isolation I plan to do next, as right now that seems a bit scary. But like everything in life, there is a first time, and things usually get easier after that if you just work through it and practice.